 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025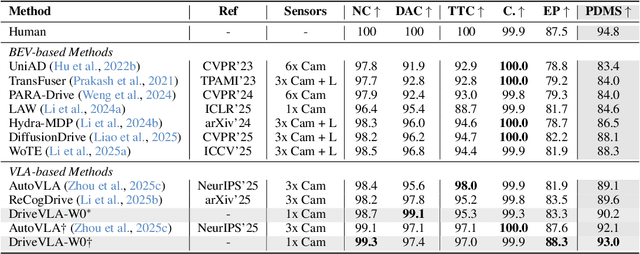
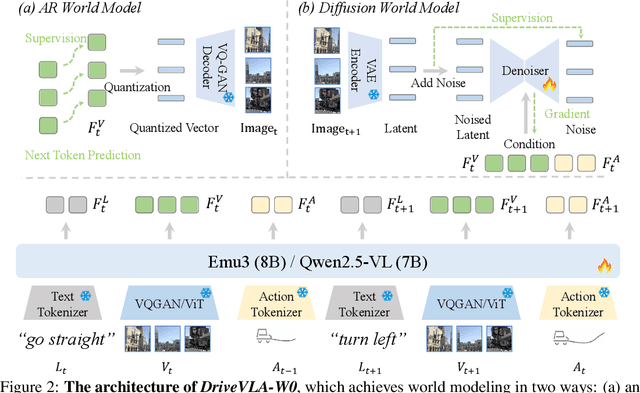

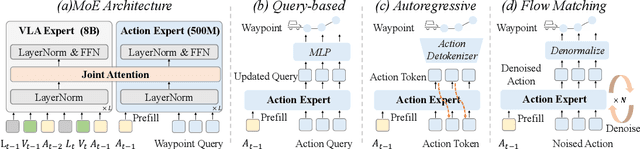
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
Visual Recognition by Request
Jul 28, 2022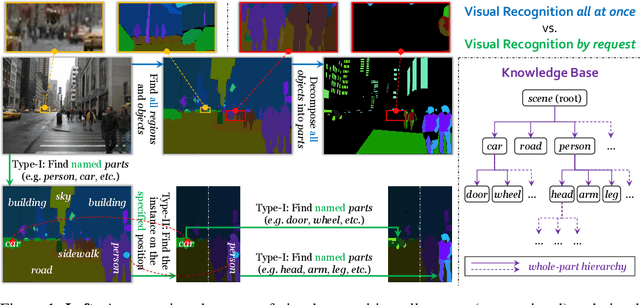
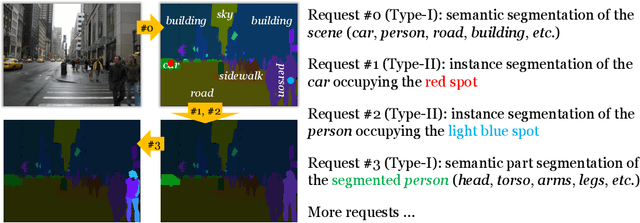

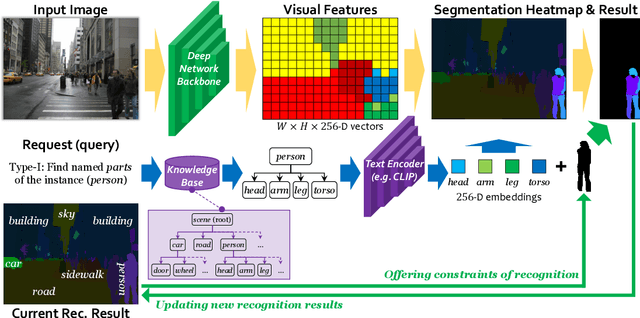
In this paper, we present a novel protocol of annotation and evaluation for visual recognition. Different from traditional settings, the protocol does not require the labeler/algorithm to annotate/recognize all targets (objects, parts, etc.) at once, but instead raises a number of recognition instructions and the algorithm recognizes targets by request. This mechanism brings two beneficial properties to reduce the burden of annotation, namely, (i) variable granularity: different scenarios can have different levels of annotation, in particular, object parts can be labeled only in large and clear instances, (ii) being open-domain: new concepts can be added to the database in minimal costs. To deal with the proposed setting, we maintain a knowledge base and design a query-based visual recognition framework that constructs queries on-the-fly based on the requests. We evaluate the recognition system on two mixed-annotated datasets, CPP and ADE20K, and demonstrate its promising ability of learning from partially labeled data as well as adapting to new concepts with only text labels.
Active Pointly-Supervised Instance Segmentation
Jul 23, 2022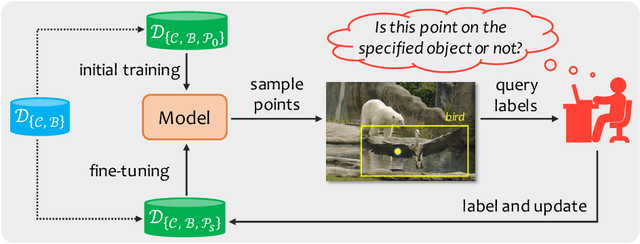
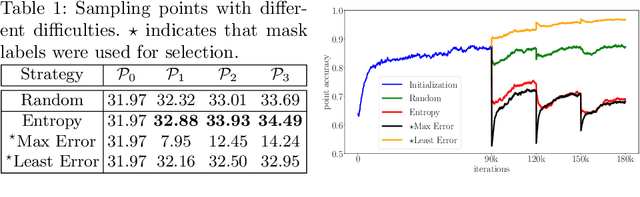
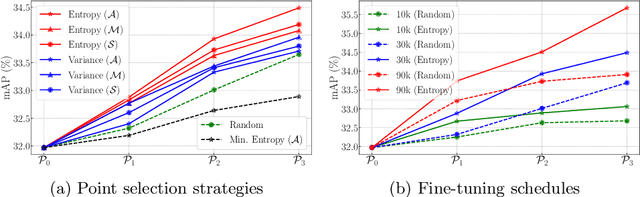

The requirement of expensive annotations is a major burden for training a well-performed instance segmentation model. In this paper, we present an economic active learning setting, named active pointly-supervised instance segmentation (APIS), which starts with box-level annotations and iteratively samples a point within the box and asks if it falls on the object. The key of APIS is to find the most desirable points to maximize the segmentation accuracy with limited annotation budgets. We formulate this setting and propose several uncertainty-based sampling strategies. The model developed with these strategies yields consistent performance gain on the challenging MS-COCO dataset, compared against other learning strategies. The results suggest that APIS, integrating the advantages of active learning and point-based supervision, is an effective learning paradigm for label-efficient instance segmentation.
Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation
Apr 12, 2021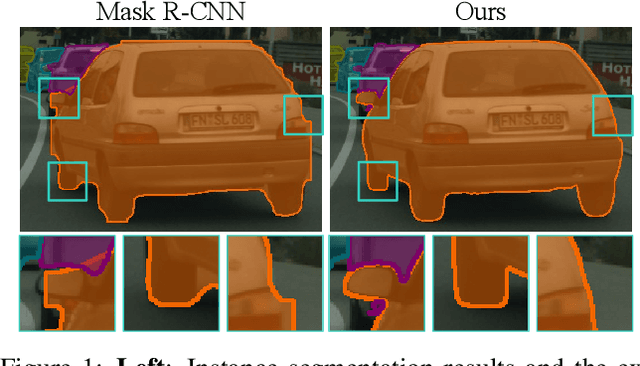
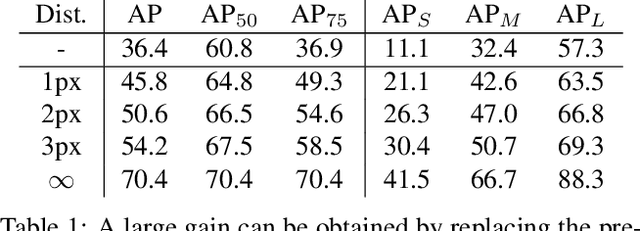
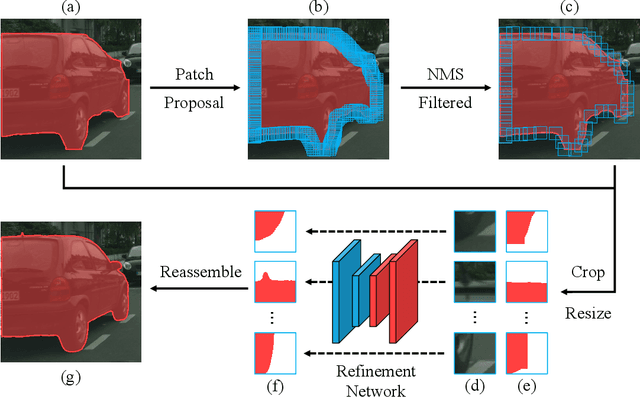
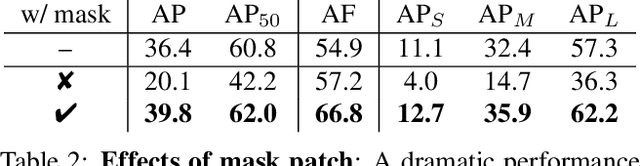
Tremendous efforts have been made on instance segmentation but the mask quality is still not satisfactory. The boundaries of predicted instance masks are usually imprecise due to the low spatial resolution of feature maps and the imbalance problem caused by the extremely low proportion of boundary pixels. To address these issues, we propose a conceptually simple yet effective post-processing refinement framework to improve the boundary quality based on the results of any instance segmentation model, termed BPR. Following the idea of looking closer to segment boundaries better, we extract and refine a series of small boundary patches along the predicted instance boundaries. The refinement is accomplished by a boundary patch refinement network at higher resolution. The proposed BPR framework yields significant improvements over the Mask R-CNN baseline on Cityscapes benchmark, especially on the boundary-aware metrics. Moreover, by applying the BPR framework to the PolyTransform + SegFix baseline, we reached 1st place on the Cityscapes leaderboard.
Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization
Oct 10, 2019
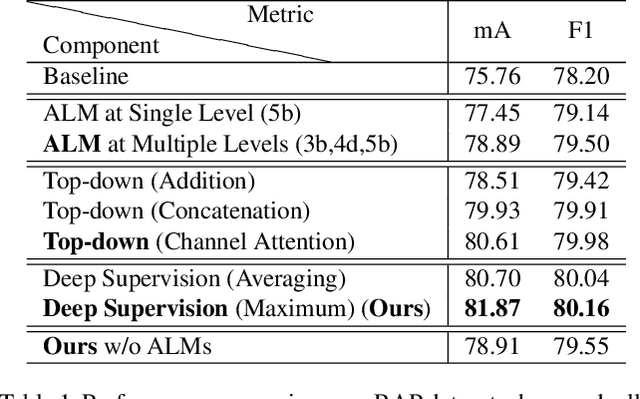
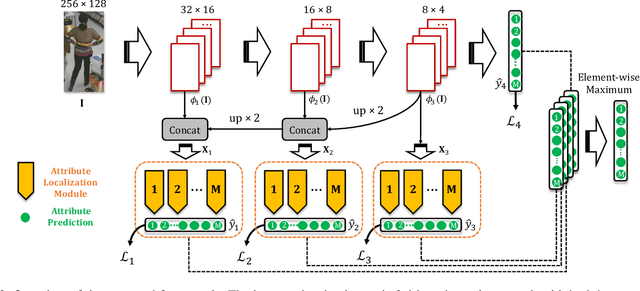
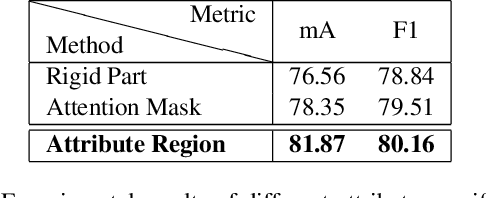
Pedestrian attribute recognition has been an emerging research topic in the area of video surveillance. To predict the existence of a particular attribute, it is demanded to localize the regions related to the attribute. However, in this task, the region annotations are not available. How to carve out these attribute-related regions remains challenging. Existing methods applied attribute-agnostic visual attention or heuristic body-part localization mechanisms to enhance the local feature representations, while neglecting to employ attributes to define local feature areas. We propose a flexible Attribute Localization Module (ALM) to adaptively discover the most discriminative regions and learns the regional features for each attribute at multiple levels. Moreover, a feature pyramid architecture is also introduced to enhance the attribute-specific localization at low-levels with high-level semantic guidance. The proposed framework does not require additional region annotations and can be trained end-to-end with multi-level deep supervision. Extensive experiments show that the proposed method achieves state-of-the-art results on three pedestrian attribute datasets, including PETA, RAP, and PA-100K.